Initial Architecture
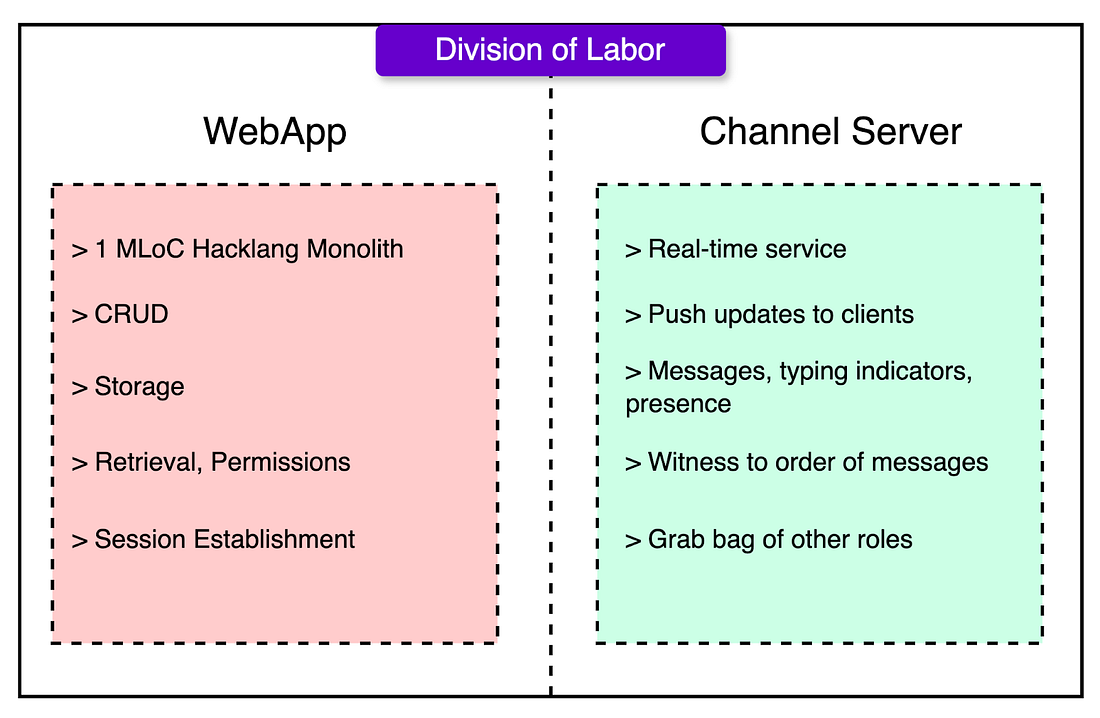
- Web App (Hacklang)
- Auth, permissions, and storage
- API endpoints and job queuing
- Session bootstrapping and metadata lookup
- Channel Server (Java)
- WebSocket handling
- Real-time message fan-out
- Typing indicators, presence blips, and ordering guarantees
Problems with the initial architecture
- The monolith grew brittle as testing got harder and deployment risk went up.
- The channel server held state, which complicated recovery and scaling.
- Server temporarily held message in memory before handing over to web app for persistence
- Server also held state to maintain web socket connections
- Transient presence and typing statuses were also held in memory and broadcasted in real time
- Dependencies between the two made failures messy. If the web app went down, the channel server couldn’t persist messages, but might still tell users they’d sent them.
Atomic Broadcasts
It is a classical problem in distributed systems.
Multiple nodes received the same messages in the same order, and every message comes from someone, it guarantees three core properties
- Validity: If a user sends a message, it eventually gets delivered.
- Integrity: No message appears unless it was sent.
- Total Order: All users see messages in the same sequence.
Send Flow
Initial
In real-time apps, low latency is a necessity. The initial flow prioritised responsiveness. The client sends the message directly to the channel server which then
- Broadcasts it to all clients
- Send an acknowledgement to the sender
- Hand it off to the web app for indexing, persistence and deferred work
However, there are some issues. If the server crash after confirming the message but before persisting it, the message will not be persisted.
- Stateful servers meant complex failover logic and careful coordination.
- Deferred persistence meant the UI could technically lie about message delivery.
- Retries and recovery had to reconcile what was shown vs. what was saved.
Slack patched with persistent buffers and retry loops, but this added complexity.
Updated
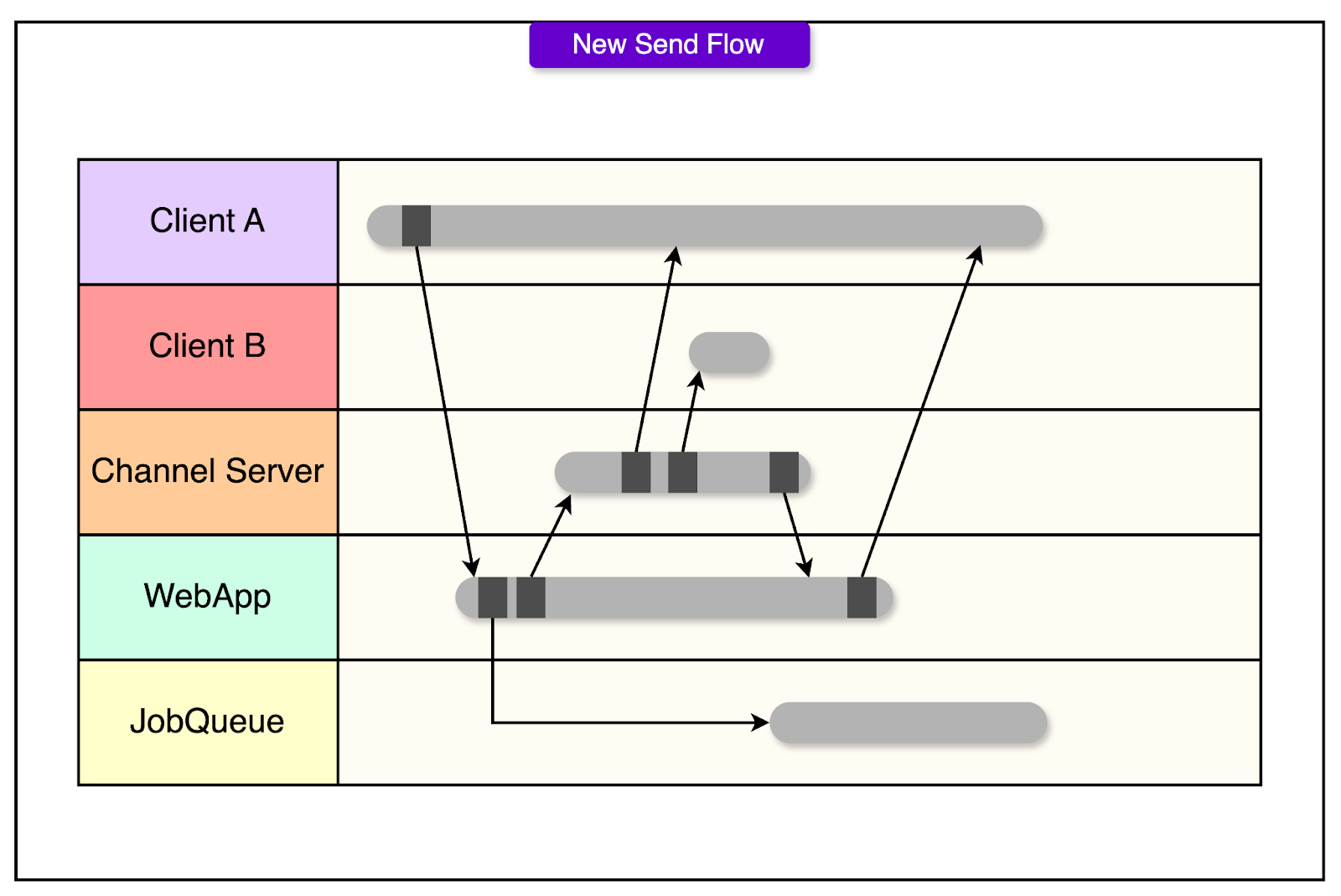
- The client sends the message via HTTP POST to the web app
- The web app logs the message to the job queue (persistence, indexing, and parsing all happen here)
- Only then does it invoke the channel server to broadcast the message in real-time
Improvements
- Crash safety: If anything goes down mid-flow, either the message persists or the client gets a clear failure.
- Stateless channel servers: Without needing local buffers or retries, they become easier to scale and maintain.
- Latency preserved: Users still see messages immediately, because the real-time broadcast happens fast, even while persistence continues in the background.
- Web Socket not needed: That’s a big deal for mobile clients responding to notifications, where setting up a full session just to reply was costly.
Session Initialisation
Originally Slack uses a method called Real-Time Messaging Start (RTM Start).
When a client initiated a session, the web app assembled a giant JSON payload: user profiles, channel lists, membership maps, unread message counts, and a WebSocket URL. This was meant to be a keyframe: a complete snapshot of the team’s state, so the client could start cold and stay in sync via real-time deltas.
However, there were several issues when the teams got big
- For large organizations (10,000+ users), it ballooned to tens of megabytes.
- Clients took tens of seconds just to parse the response and build local caches.
- If a network partition hit, thousands of clients would reconnect at once, slamming the backend with redundant work.
- Payload size grew quadratically with team size. Every user could join every channel, and the web app calculated all of it.
- All this work happened in a single data centre, creating global latency for users in Europe, Asia, or South America.
Flannel: Cache the cold start
Flannel is a purpose-built microservice that acts as a stateful, geo-distributed cache for session bootstrapping.
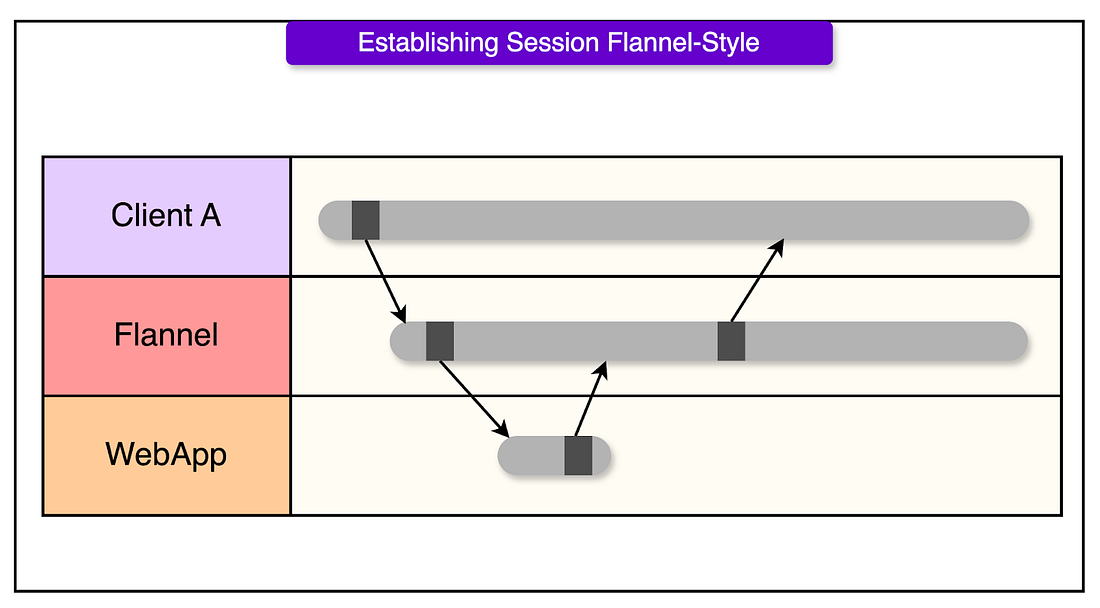
- It maintains a pre-warmed in-memory cache of team metadata
- Listens to WebSocket events to keep that cache up to date, just like a client would
- It serves session boot data locally, from one of many regional replicas
- Sits astride the WebSocket connection, terminating it and handling session validation
The problem: Message Duplication
Here’s how it happens:
- A mobile client sends a message.
- Network flakiness delays the acknowledgment.
- The client times out and retries.
- Both messages make it through, or one makes it twice, and now the user wonders what just happened.
On the backend, retries and failures get more serious. A message might:
- Reach the channel server but fail to persist
- Persist to the job queue but never push
- Push to some clients and not others
Solution: Idempotency
Each message includes a client-generated ID or salt. When the server sees the same message ID again, it knows it’s not a new send.
Solution: Queueing Architecture (Kafka)
Slack uses Kafka for durable message queuing and Redis for in-flight, fast-access job data. Kafka acts as the system’s ledger and Redis provides short-term memory.
To ensure that there is a consistent ordering of messages, the order of messages is determined by the order in which the web app enqueues the messages on to Kafka.
Redis is used to get an updated status of the job processing.