Why was the SAGA Pattern introduced?
The SAGA pattern was created to solve the problem of long-lived transactions in database systems.
Traditional transactions were designed to be short-lived, locking resources for a minimal duration to maintain ACID guarantees. However, there are some operations such as generating a complex bank statement, processing large historical datasets, or reconciling multi-step financial workflows, require holding locks for extended periods of time.
These long-running transactions created bottlenecks by tying up resources, reducing system concurrency, and increasing risk of failure.
How does SAGA aim to fix these issues?
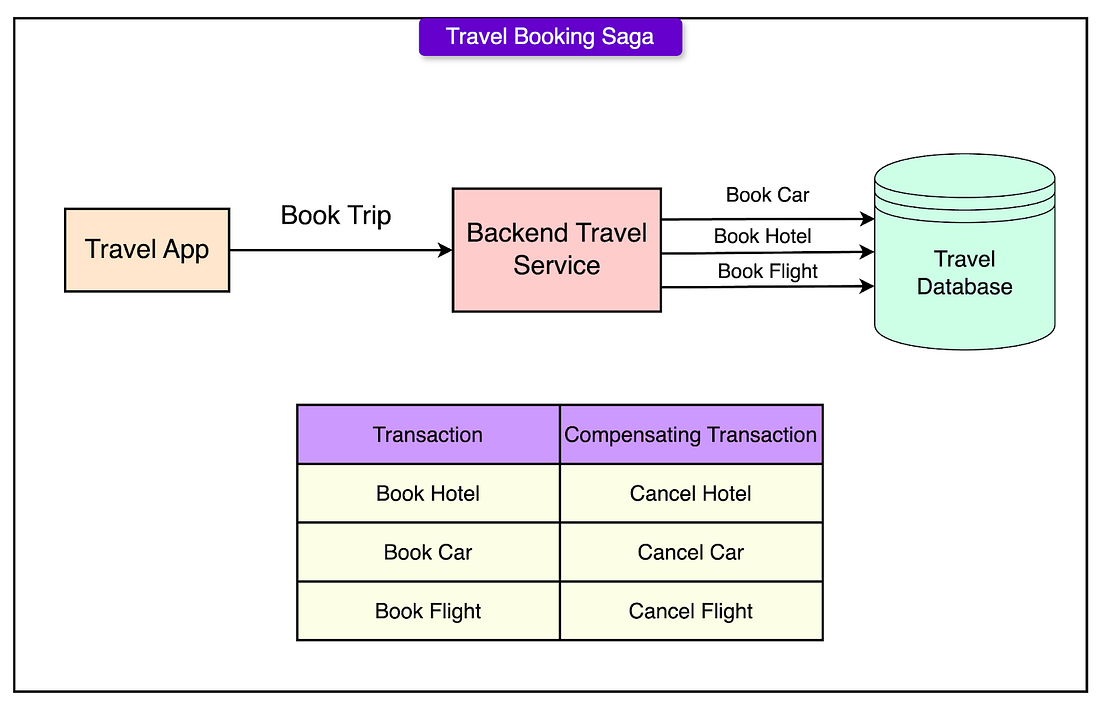
- A single logical operation is split into a sequence of smaller sub-transactions.
- Each sub-transaction is executed independently and commits its changes immediately.
- If all sub-transactions succeed, the Saga as a whole is considered successful.
- If any sub-transaction fails, compensating transactions are executed in reverse order to undo the changes of previously completed sub-transactions.
Key Technical Points about SAGA
- Sub-transactions must be independent: The successful execution of one sub-transaction should not directly depend on the outcome of another. This independence allows for better concurrency and avoids cascading failures.
- Compensating transactions are required: For every sub-transaction, a corresponding compensating action must be defined. These compensating transactions semantically “undo” the effect of their associated operations. However, the system may not always be able to return to the exact previous state; instead, it aims for a semantically consistent recovery.
- Atomicity is weakened: Unlike traditional transactions, where partial updates are never visible, in a Saga, intermediate states are visible to other parts of the system. Partial results may exist temporarily until either the full sequence completes or a failure triggers rollback through compensation.
- Consistency is preserved through business logic: Instead of relying on database-level transactional guarantees, Sagas maintain application-level consistency by ensuring that after all sub-transactions and compensations, the system is left in a valid and coherent state.
- Failure management is built in: Sagas treat failures as an expected part of the system’s operation. The pattern provides a structured way to handle errors and maintain resilience without assuming perfect reliability
SAGA Execution Models
Single Database Execution
In this environment, executing a saga requires two main components:
Saga Execution Coordinator (SEC)
The Saga Execution Coordinator is a process that orchestrates the execution of all the sub-transactions in the correct sequence. It is responsible for:
- Starting the saga
- Executing each sub-transaction one after another
- Monitoring the success or failure of each sub-transaction
- Triggering compensating transactions if something goes wrong
The SEC ensures that the saga progresses correctly without needing distributed coordination because everything is happening within the same database system.
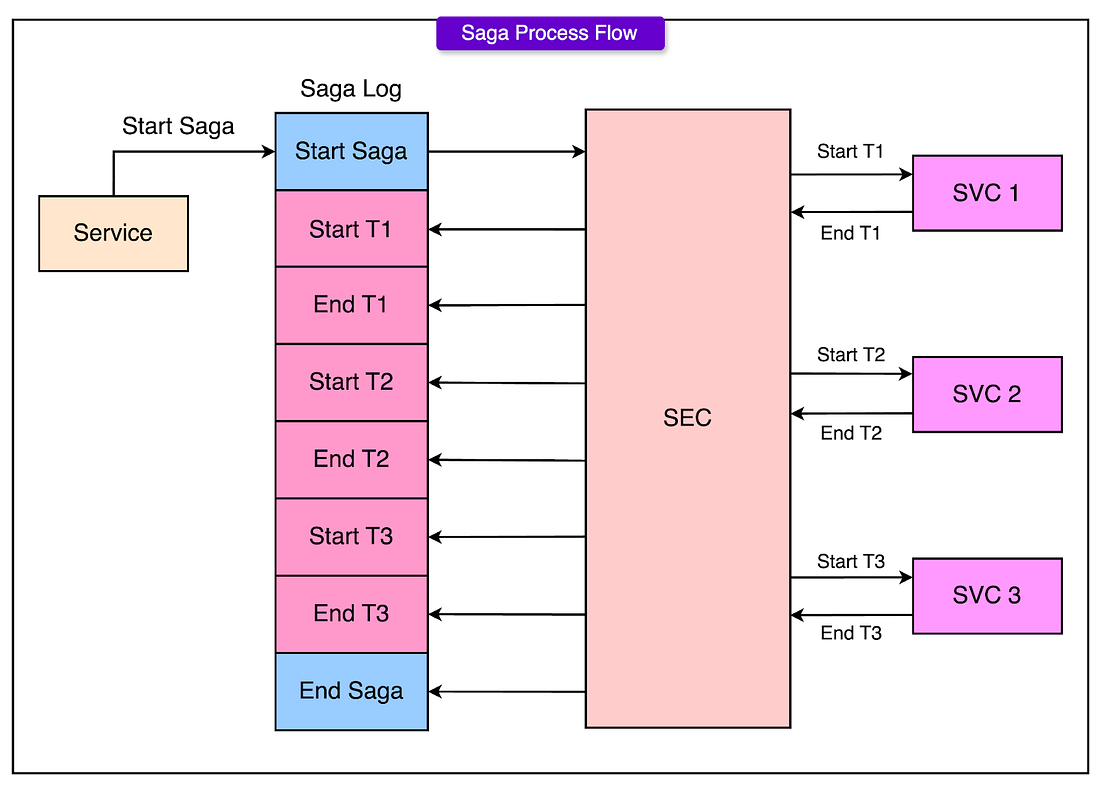
SAGA Log
The Saga Log acts as a durable record of everything that happens during the execution of a saga. Every major event, starting a saga, beginning a sub-transaction, completing a sub-transaction, beginning a compensating transaction, completing a compensating transaction, ending a saga, is written to the log.
The Saga Log guarantees that even if the SEC crashes during execution, the system can recover by replaying the events recorded in the log. This provides durability and recovery without relying on traditional transaction locking across the entire saga.
Failure Handling
Handling failures in a single database saga relies on a strategy called backward recovery.
This means that if any sub-transaction fails during the saga’s execution, the system must roll back by executing compensating transactions for all the sub-transactions that had already completed successfully.
Here’s how the process works:
- Detection of Failure: The SEC detects that a sub-transaction has failed because the database operation either returns an error or violates a business rule.
- Recording the Abort: The SEC writes an abort event to the Saga Log, marking that the forward execution path has been abandoned.
- Starting Compensations: The SEC reads the Saga Log to determine which sub-transactions had been completed. It then begins executing the corresponding compensating transactions in the reverse order.
- Completing Rollback: Each compensating transaction is logged in the Saga Log as it begins and completes.
After all necessary compensations have been successfully applied, the saga is formally marked as aborted in the log.
Multiple Database Execution
An example of an implementation of SAGA in a multi database execution environment is the Halo 4 Stats Service, we will next explore the architecture of it.
Service Architecture
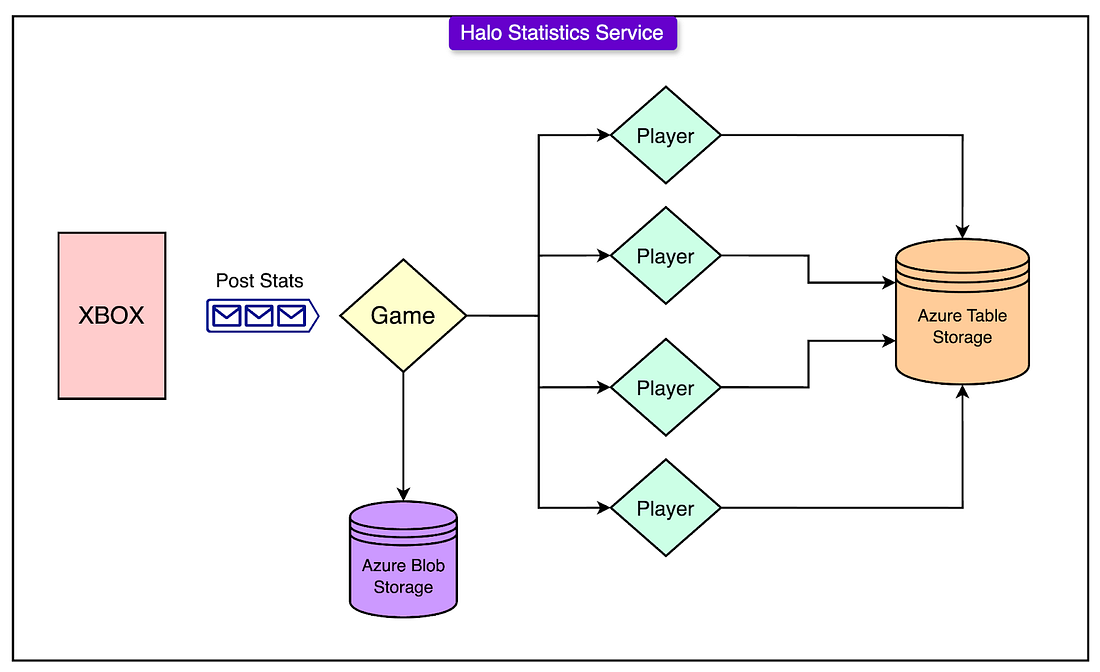 Important components:
Important components:
- Azure Table Storage: A No-SQL key-value store, to store player data. Each player’s data is assigned to a separate partition, allowing for highly parallel reads and writes
- Orleans Actor Model: Adopting the Microsoft Orleans Model, which is based on the actor model
- Game grains handled the aggregation of statistics for a game session
- Player grains were responsible for persisting player’s statistics. A Player Grain is a logical unit that represents a single player’s data and behaviour inside the server-side application.
- Azure Service Bus: Used as a message queue and a distributed, durable log. When a new game is completed, a message containing the statistics payload is published to the Service Bus
- Stateless Frontend Services: Accepts raw statistics from Xbox clients, then publish them to the service bus
What is the difference between partitioning a database and sharding it?
Partitioning a database is dividing a database table into smaller, more manageable pieces, typically within a single database instance
Sharding is distributing data across multiple database instances
If you’re hitting vertical scaling limits (CPU/RAM/disk on one server), sharding is what you need. If you’re optimizing query performance within a big table, partitioning is the tool.
Summary: After a game, each of the stateless frontend services will then publish the statistics to the Azure Service Bus.
A stateless worker that subscribes to the service bus will then deserialise the message and extract the game session or any other context and call Orleans to activate the correct game grain.
The game grain then stores relevant information in the Azure Blob Storage and sends update requests to the relevant Player Grains. If the player grain is not activated, it will be activated.
Each player grain will then update the player stats in the Azure Table Storage
SAGA Application
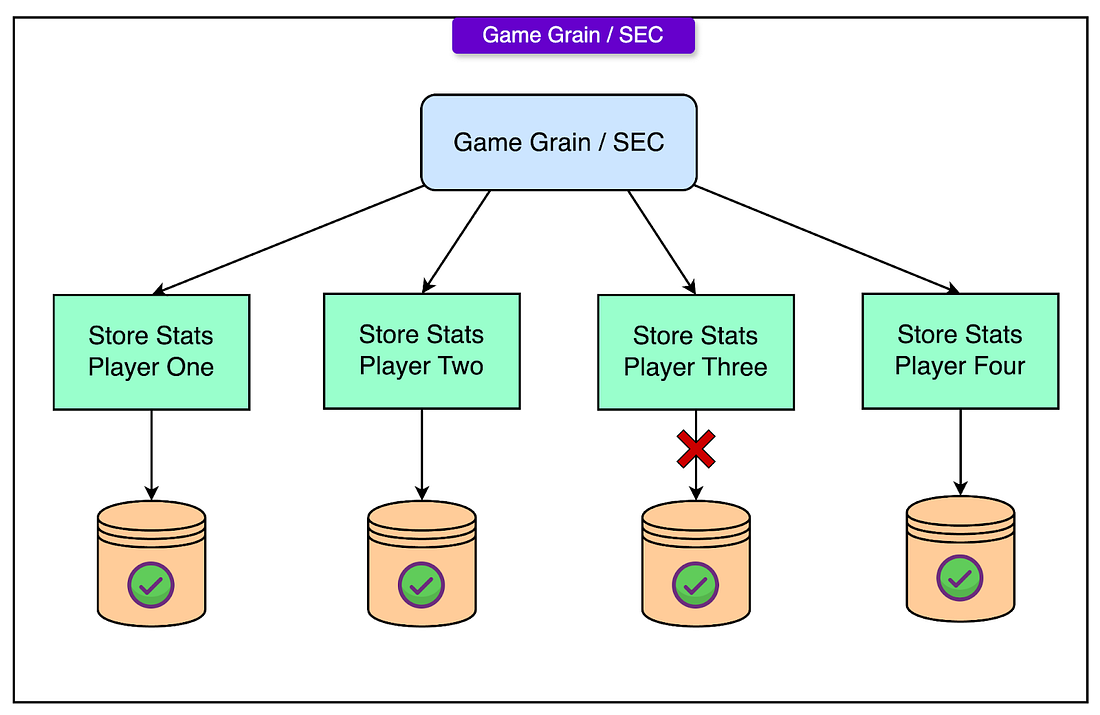 The typical sequence was:
The typical sequence was:
- Aggregation: After a game session ended, the Game Grain aggregated statistics from the participating players.
- Saga Initiation: A message was logged in the Azure Service Bus indicating the start of a saga for updating statistics for that game.
- Sub-requests to Player Grains: For each player in the game (up to 32), the Game Grain sent individual update requests to their corresponding Player Grains. Each Player Grain then updated its player’s statistics in Azure Table Storage.
- Logging Progress: Successful updates and any errors were recorded through the durable messaging system, ensuring that no state was lost even if a process crashed.
- Completion or Failure: If all player updates succeeded, the saga was considered complete. If any player update failed (for example, due to a temporary Azure storage issue), the saga would not be rolled back but would move into a forward recovery phase.
Forward Recovery Strategy
Rather than using traditional backward recovery (rolling back completed sub-transactions), the Halo 4 team implemented forward recovery for their statistics sagas.
The main reasons for choosing forward recovery are as follows:
- User Experience: Players who had their stats updated successfully should not see those stats suddenly disappear if a rollback occurred. Rolling back visible, successfully processed data would create a confusing and poor experience.
- Operational Efficiency: Retrying only the failed player updates was more efficient than undoing successful writes and restarting the entire game processing.
The forward recovery process:
- If a Player Grain failed to update its statistics (for example, due to storage partition unavailability or quota exhaustion), the system recorded the failure but did not undo any successful updates already completed for other players.
- The failed update was queued for a retry using a back-off strategy. This allowed time for temporary issues to resolve without overwhelming the storage system with aggressive retries.
- Retried updates were required to be idempotent. That is, repeating the update operation would not result in duplicated statistics or corruption. This was achieved by relying on database operations that safely applied incremental changes or overwrote fields as necessary.
- Successful retries eventually brought all player records to a consistent state, even if it took minutes or hours to do so after the original game session ended.