Fixed Windows
In fixed windows, the idea is that we partition our time in windows, for example, a possible window is every clock hour. So 1pm - 2pm is one window, and the next is 2pm - 3pm
Within each window, we can set a limit to the number of requests from a user
Pros
- Simple to implement
- Easy to understand for the users
Cons
- This implementation will allow bursts of up to 2x the limit, when a user spams requests just before and just after the window
Sliding Windows
In sliding windows, instead of refreshing all the requests based on the window, we refresh the request one request at the time
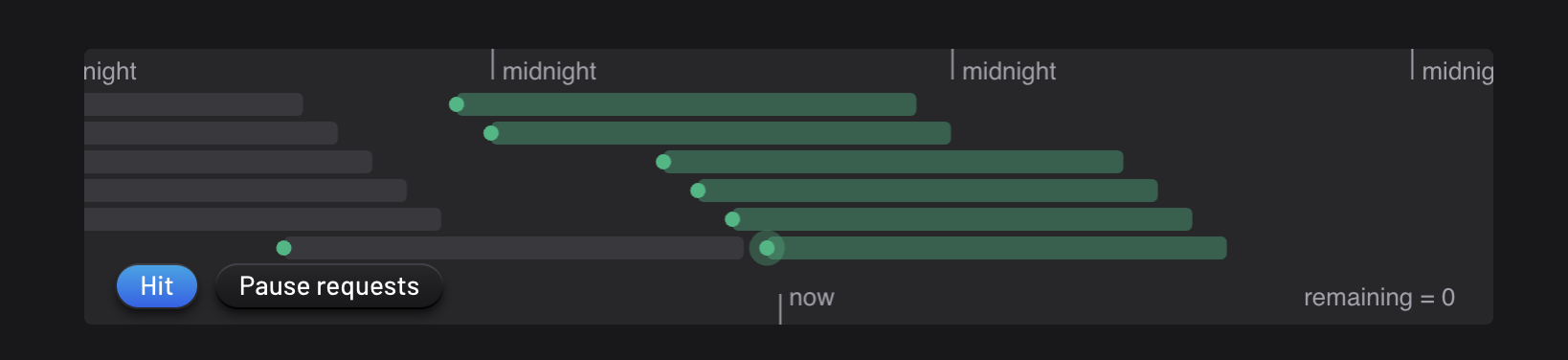
What this means is that each request will have an “interval”, and if the current time is within that interval, it takes up a slot in our total capacity that we have. Only when the current time is outside of the interval, then our capacity will increase
Pros
- Smooths the distribution of request traffic
- Well suited for high loads
Cons
- Less predictable for users than fixed windows
- Storing timestamps for each request is resource-intensive
As one of the pros of sliding windows is that it is suited for high loads, the con that it is resource-intensive is counterproductive. As such, there is a variant that makes it less resource intensive
Approximated Sliding Window
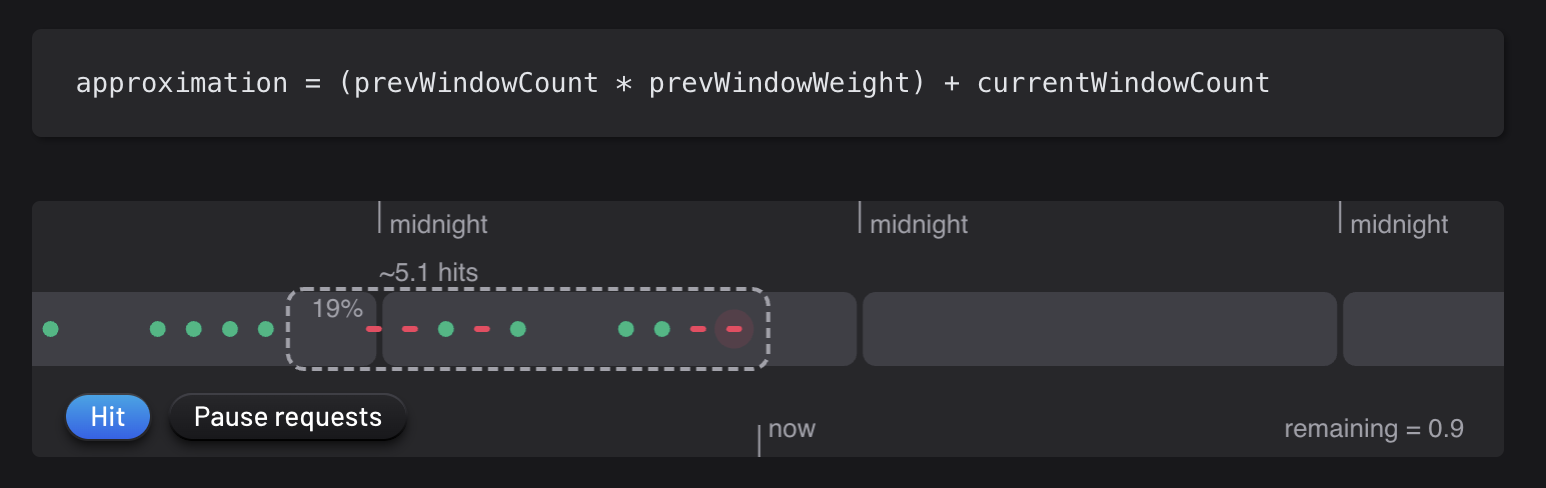 The idea is that we have a window that keeps track of the percentage of the current window (in dotted) in the previous and next window
The idea is that we have a window that keeps track of the percentage of the current window (in dotted) in the previous and next window
This percentage is then used as a weight to count the number of requests in each window.
This way, we do not need to keep track of the timestamp of each request. This is the current implementation for Cloudflare.
Token Buckets
For token buckets, the idea is that we have a bucket consisting of x many number of tokens. When a request is fired, it costs one token from that bucket. At every y seconds, a token is added to that bucket. This bucket will have a capacity.
Pros
- Allows for bursts of traffic
- Flexible for users, allowing for traffic spikes within an acceptable range
Cons
- If the underlying system cannot handle spikes, it may lead to outages
Real World Examples
- Stripe uses a token bucket in which each user gets a bucket with
limit = 500,refillInterval = 0.01s, allowing for sustained activity of 100 requests per second, but bursts of up to 500 requests. (Implementation details.) - OpenAI’s free tier for GPT-3.5 is limited to 200 requests per day using a token bucket with
limit = 200andrefillInterval = 86400s / 200, replenishing the bucket such that at the end of a day (86,400 seconds) an empty bucket will be 100% filled. They refill the bucket one token at a time.
Wrapping Up
- If you need a simple rate limiter or predictable window start times, use a fixed window.
- If you need traffic smoothing for a high volume of requests, consider using an approximated sliding window.
- If you need to support bursts of traffic while enforcing a lower average long-term rate for requests, use a token bucket.